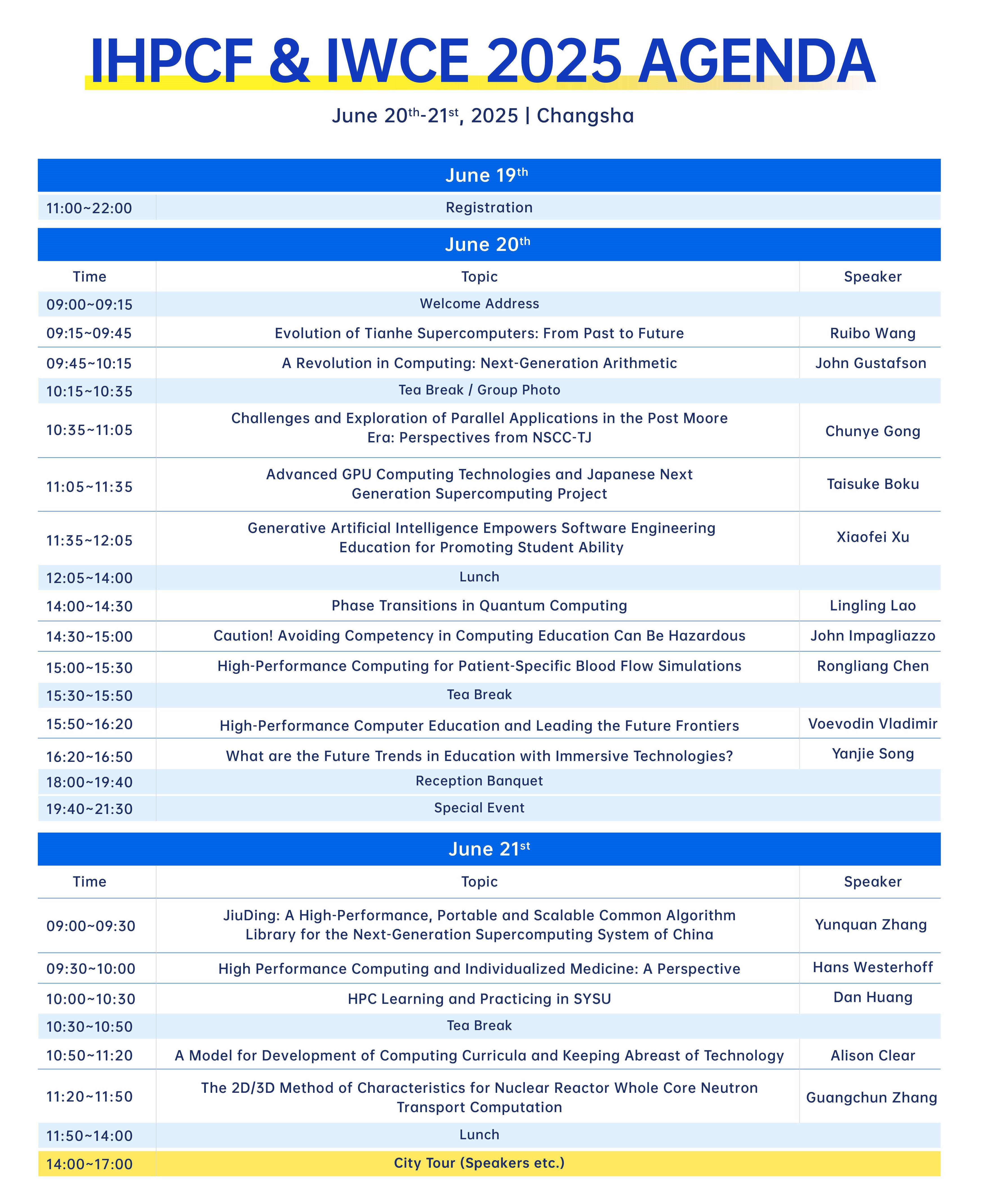
Agenda
Invited Speakers

Ruibo Wang
National Key Laboratory of Parallel and Distributed Computing (PDL), China
Ruibo Wang is a professor of computer science at the National Key Laboratory of Parallel and Distributed Computing (PDL) and a core member of the Tianhe supercomputing team. He has played a pivotal role in the development of multiple generations of Tianhe supercomputers and currently serves as the Vice Chief Designer of the latest generation. Prof. Wang is also the Principal Investigator of a project under National Key Research and Development Program of China. His research interests include operating systems, file systems, and resource scheduling in high-performance computing (HPC). He has published extensively in major conferences and journals such as SC, ICS, CLUSTER, IPDPS, and TPDS. His work has achieved significant impact, including securing top rankings on internationally recognized benchmarks such as Graph500, GreenGraph500, and IO500. He has been invited to deliver keynote speeches at major international conferences, including the International Supercomputing Conference (ISC), Russia Supercomputing Days, and the Korean Supercomputing Conference.

John Gustafson
National University of Singapore, Singapore
Fellow
Institute of Electrical and Electronics Engineers (IEEE)
Prof. John L. Gustafson is Chief Scientist of Vq Research and a Visiting Scholar at Arizona State University. Previously, he has been a Senior Fellow at AMD and a Director of Intel Labs. He is best known for his 1988 argument showing that parallel processing performance need not be limited by Amdahl's law, now generally known as Gustafson's law. He is a recipient of the inaugural Gordon Bell Prize and is a Golden Core member of IEEE.
A Revolution in Computing: Next-Generation Arithmetic
For 50 years, "floating-point operations per second" (FLOPS) has been the currency of technical computing performance. But the rise of AI and the end of Moore's law have made us realize that IEEE standard floating-point (invented by Intel in 1977) is long overdue for replacement. Floating-point format is an imitation of a human-centric format, scientific notation. Just as decimal digits are a human-friendly but inefficient way to represent integers in electronic computers, floating-point format is a human-friendly but inefficient way to represent real numbers. I will present a new way to represent real numbers on computers that is both mathematically sound and follows engineering design goals. The elegant and simple approach can more than double speed and energy-efficiency for everything from Machine Learning to Computer Graphics to High-Performance Computing. This is a watershed, a revolution. And it is well underway.

Chunye Gong
National Supercomputing Center in Tianjin (NSCC-TJ), China
Chunye Gong is a professor and deputy director of the National Supercomputing Tianjin Center (NSCC-TJ). He is responsible for the research and development of Tianhe's new generation of applications, focusing on high-performance computing and automatic performance optimization. He led his team to develop Graph500, which has won multiple world championships, and developed the grid generation industrial software YHGrid; The Tianhe Supercomputing Innovation Application Team was selected as the first National Excellent Engineer Team of China.

Taisuke Boku
Center for Computational Sciences, University of Tsukuba, Japan
Vice Chair
High Performance Computing Infrastructure (HPCI) Consortium
Taisuke Boku has been the Director for Center for Computational Sciences, University of Tsukuba, a co-designing center with both application researchers and HPC system researchers. He played a central roles for development of original supercomputers in the center including CP-PACS (ranked as number one in TOP500 in 1996), FIRST, PACS-CS, HA-PACS, Cygnus and Pegasus systems, the representative supercomputers in Japan. He was the President of HPCI (High Performance Computing Infrastructure) Consortium in Japan in 2020-2022, and also currently the Vice President in 2024-2026. He received ACM Gordon Bell Prize in 2011. He is currently one of the Program Directors of the Feasibility Study of the Next Generation Supercomputer in Japan under MEXT, and also one of the Program Directors of the Program for Promoting Research on the Supercomputer Fugaku.
Advanced GPU Computing Technologies and Japanese Next Generation Supercomputing Project
In this talk, I will introduce our GPU-CPU combined supercomputer based on NVIDIA GH200 Superchip at first. GH200 consists of Grace CPU and Hopper GPU connected via ultra high-speed link of NVLINK-C2C which easily makes a shared address space memory access between CPU and GPU. I will introduce how the programming and performance are improved by more user-friendly coding on several benchmarks and applications. The second half of my talk is for a brief introduction on Japan's next generation supercomputing project with GPU-based massively parallel supercomputer. The project has just started and I like to share an early stage design and target of the system in 2025 time frame.

Xiaofei Xu
Faculty of Computing, Harbin Institute of Technology, China
Fellow
China Computer Federation (CCF)
Prof. Xiaofei Xu, the fellow of China Computer Federation (CCF), is the former vice president of Harbin Institute of Technology (HIT), current full professor and doctoral supervisor in the Faculty of Computing at HIT. He is also the vice director of China MoE (Ministry of Education) University Teaching Steering Committee on Software Engineering, vice director of MoE University Teaching Steering Committee on Digital Education and Innovation, director of the Execution Committee of the Union of the Associations on MOOCs in Chinese Universities, executive vice chairman of the Association of Chinese University MOOCs on Computer Education. He has won three National Teaching Awards of China, (Two first-class prizes, one second-class prize), and more than ten provincial awards on teaching or research achievements. He is the winner of IEEE TCSVC Outstanding Leadership Award, CCF Outstanding Education Award, CCF 60-Years Outstanding Contribution Award, CCF Life-Time Academic Contribution Award on Service Computing.
Generative Artificial Intelligence Empowers Software Engineering Education for Promoting Student Ability
In the digital and intelligent era, generative artificial intelligence (GenAI) plays an important role in promoting development of digital higher education, and brings also the new chances and challenges to software engineering education. This speech will analyzes the impact of GenAI and Large Language Models (LLMs) on software engineering technology, industrial occupation, as well as the changes of teaching contents and models, and learning methods on software engineering. With the purpose of GenAI to improve students' professional ability, this paper explores the new models and methods of GenAI-empowered software engineering education, expounds the strategy and methods of reforming software engineering education by means of LLMs, and proposes an GenAI-empowered ability cultivation, assessment and certification system of software engineering to improve professional ability, which provides guidance for the reform and practice of software engineering education in the digital era.

Lingling Lao
National Key Laboratory of Parallel and Distributed Computing (PDL), China
Lingling Lao is a professor of computer science at the National Key Laboratory of Parallel and Distributed Computing (PDL). She holds a bachelor's degree in electronics from Harbin Institute of Technology, a master's degree in Electronics from Northwestern Polytechnical University, and a PhD in quantum computing from QuTech, Delft University of Technology in the Netherlands. Afterwards, she joined Prof. Dan Browne’s group as a Research Fellow at the Department of Physics and Astronomy, University College London. Her research interests include quantum compilation, quantum error correction, fault-tolerant quantum computing.

John Impagliazzo
Hofstra University, United States
Fellow
Distinguished Educator
Institute of Electrical and Electronics Engineers (IEEE)
Association for Computing Machinery (ACM)
Professor Emeritus John Impagliazzo chaired the committee that produced the 2016 ACM/IEEE Computer Engineering Curriculum Report (CE2016) and was the principal co-author and editor of CE2004. Additionally, he was a committee member who produced the ACM/IEEE Computing Curricula 2005 Report (CC2005), which defined computing disciplines and has become one of the most used documents worldwide. He co-authored the information technology (IT2017) report and was a principal co-author of the 2020 global computing curricular report (CC2020). Impagliazzo chaired the IFIP Working Group 9.7 (History of Computing), served for many years on the IEEE History Committee, chaired the ACM Accreditation Committee for twelve years, and served in various capacities on the ACM Education Board for three decades. He is an ABET program evaluator for both computing and engineering programs. As a program evaluator, team chair for governments and agencies, or an expert consultant, he has evaluated over one hundred computing and engineering programs worldwide. Impagliazzo was the founding editor-in-chief of the ACM Inroads magazine, created the IEEE Transactions on Technology and Society, produced eighteen books, published hundreds of articles, and helped develop a history of computing. Impagliazzo is a Fellow and Life Member of IEEE and a Distinguished Educator of ACM.
Caution! Avoiding Competency in Computing Education Can Be Hazardous
This presentation explores ways in which competency in computing and engineering can become sustainable in a world where technological digital advances continuously infuse people’s lives. Educational computing without competency can endanger how students learn and graduates operate in the workplace. Competency and technical performance have become central to informing students of their responsibilities to society as they enter the workplace or continue in higher education. Competency-based learning and teaching in computing and engineering have transformed into the current digital age. Efforts such as the 2024 “Metaverse Services in Computing and Engineering Education” paper, the 2023 “Infinite Possibilities: Report on the Digital Development of Global Higher Education” report, the ACM/IEEE “Computing Curricula 2020: Paradigms for Global Computing Education” report, and the 2019 “Chinese Computer Education for Sustainable Competence” (Blue Book) report support this claim. These publications directly or indirectly support a sustained competency transformation for the digital age, even though educators have yet to embrace competency-based learning in their curricula. This presentation provides helpful suggestions and shows how competency can enhance teaching and learning beyond the current educational norms.

Rongliang Chen
Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences, China
Rongliang Chen received his B.Sc. in applied mathematics from Hunan University and PhD in computational mathematics from a joint program between Hunan University and University of Colorado Boulder. After graduation, he joined the Shenzhen Institutes of Advanced Technology Chinese Academy of Sciences as an assistant professor and promoted to associate professor in Jan 2015 and full professor in Jan 2023. He research focus on the development of high-performance computing algorithms and software for engineering applications, including blood flow simulations, aerodynamic analysis of aerospace vehicles, and large-scale pollutant dispersion simulations.

Voevodin Vladimir
Lomonosov Moscow State University, Russia
Director
Research Computing Center of MSU
Chair of the Department
Computational Mathematics and Cybernetics Faculty of MSU
Vladimir V. Voevodin has developed a novel approach for deep analyses, transformation and optimization of large codes based on the innovative theory of informational structures of algorithms and programs. He has contributed to the design and implementation of the following tools, software packages, systems and online resources: V-Ray, X-Com, AGORA, Parallel.ru, hpc-education.ru, hpc-russia.ru, LINEAL, Sigma, Top50, LAPTA. He has published 80 scientific papers with 4 books among them.

Yanjie Song
The Education University of Hong Kong (EdUHK), China
Associate Director
The Centre for Immersive Learning and Metaverse in Education (CILME) and The Centre for Excellence in Learning and Teaching (CELT) at EdUHK
Dr. Yanjie Song is a professor at Department of Mathematics and Information Technolog, associate director of the Centre for Immersive Learning and Metaverse in Education (CILME) and the Centre for Excellence in Learning and Teaching (CELT) at the Education University of Hong Kong. She obtained her PhD in Educational Technology at the Faculty of Education, the University of Hong Kong, and her MEd at the University of Leeds, UK. Her research focuses on AR, VR, AI, and the metaverse in education. She has led her team in developing award-winning applications like "VocabGo", "m-Orchestrate", and the metaverse platform "Learningverse" which is further being developed into LearningverseVR with VR and generative AI. Her team holds several patents and has secured competitive research grants. She was among the top 2% in the Stanford list of the world's most-cited scientists in education in recent years.
What are the future trends in education with immersive technologies?
With the advancement of immersive virtual environments powered by generative AI, education is surpassing the constraints of traditional physical classrooms. This presentation explores three innovative platforms developed by the speaker’s research team: the metaverse platform – Learningverse, which integrates digital humans for interactive learning; another metaverse platform with virtual reality technology – LearningverseVR, featuring a multi-modal AI agent to support engagement; and an interactive platform – iChat, enabling the creation of customisable digital human avatars for diverse educational applications. Through empirical examples, the discussion will illustrate how these immersive environments enhance learner engagement, and academic performance. By seamlessly incorporating generative AI into immersive learning environments, these technological innovations are shaping the future of education.

Yunquan Zhang
Institute of Computing Technology, Chinese Academy of Sciences, China
Fellow
China Computer Federation (CCF)
Vice Director
The High Performance Computing Technique Committee, CCF
Yunquan Zhang is a full professor and PhD advisor of High Performance Computing Research Center, Institute of Computing Technology, Chinese Academy of Sciences in Beijing, China. He is a Member of the 14th National Committee of the Chinese People's Political Consultative Conference. He is a CCF fellow and vice director of the high performance computing technique committee, CCF. He received his BS degree in computer science and engineering from the Beijing Institute of Technology, Beijing, China in 1995. He received a PhD degree in Computer Software and Theory from the Chinese Academy of Sciences in 2000. His research interests are in the areas of high performance computing, with particular emphasis on large scale parallel application software, high-performance parallel numerical algorithms, and computational models. He has published over 200 papers in international journals and conferences proceedings. He received the Excellent Prize of President Scholarship, Chinese Academy of Sciences, the National Science and Technology Advancement Awards, 2nd Class, in 2000 and 2009, the outstanding science and technology achievement prize of the Chinese Academy of Sciences in 2017, the education achievement prize of the Chinese Academy of Sciences in 2017 and nomination of the Gorden Bell prize in 2021. His work is selected into the first world open source system contribution list in 2023. He proposed the computing power economic concept in 2018. He is the founder and publisher of Chinese TOP 100 high-performance computer list and the AIPerf 500 list. He is the founder of the PAC, CCF CPC and ACM IPCC supercomputing competitions.

Hans Westerhoff
The University of Amsterdam, Netherlands
Emeritus Professor
The University of Manchester, England
Hans Westerhoff is a long time researcher of how dynamic interactions between components of biological systems generate function. He started this in bioenergetics, non-equilibrium thermodynamics, and metabolic control analysis. After a PhD at the University of Amsterdam and stays at the University of Padova, the US National Institute of Health and the Netherlands Cancer Institute, he is now Professor of Synthetic Systems Biology at the University of Amsterdam, emeritus Professor of Systems Biology at the University of Manchester, and Professor of Microbial Physiology at the VU University Amsterdam. He is one of the drivers of the silicon human initiative and the Infrastructure for Systems Biology Europe (ISBE). He has been involved in determining molecular biochemistry properties of bacteriorhodopsin, DNA gyrase and various glycolytic enzymes of yeast and E. coli, as well as control and regulation aspects in microbial and mammalian cells. He has been a driving force behind six systems biochemistry models that integrate the molecular biochemistry of multiple enzymes into the biochemistry of pathways with various emergent properties.
High Performance Computing and individualized medicine: a perspective
Standard medicine considers only some 10 organs in a single, model individual, basing diagnosis on some 10 parameters. The ambition of individualized medicine is to promote the health of 8 billion different people however, requiring the understanding of on the order of 1035 molecules. Calculating their behavior in real time would require 1020 ExaFlops. The most powerful computers presently achieve ‘only’ 1 ExaFLOPS. Extending this by a factor of 1020 is impossible if only due to energy requirements and cost. There are ways in which the computations can be simplified. First, there are only a million types of human molecules, each with a million instantiations per cell. The integral behavior of their instantiations can mostly be described well by their average behavior using kinetics and thermodynamics. We will here present a new, biology-oriented thermodynamics that further simplifies by aggregating pseudo-conformers of molecules into ‘blends’. Second, using detailed biological information such as in Genome Scale Metabolic Maps (GeMMs), one may focus on tissues such as liver and brain and aggregate all cells of the tissue into one supercell. With this, calculating one metabolic function served by 26 tissues for all inhabitants of the planet should require a year on a Tianh2-2 computer and 20 minutes per person a PC. However, due to noisy transcription, the individual cells in a tissue or clonal cell population express the different mRNAs(the information products of the genes) at highly different, suggesting that all cells should be computed individually. Using deep sequencing data on mRNAs of thousands of individual cells in a tumor cell population, we find however that one may just as well take the average mRNA concentrations over any relevant subpopulation of cells. We shall show how this again simplifies the otherwise immense HPC task.

Dan Huang
School of Computer Science and Engineering, Sun Yat-sen University, China
National Supercomputing Center in Guangzhou (NSCC-GZ), China
Dr. Dan Huang currently is an associate professor in School of Computer Science and Engineering, Sun Yat-sen University. He received Ph.D. in computer engineering at University of Central Florida. Before this, he received master and bachelor degrees in Southeast University and Jilin University respectively. His research interests are scientific data management, high performance AI systems, parallel programming model. From November 2015 to August 2016, he worked as a researcher at the Oak Ridge National Laboratory in the United States. Currently, he is conducting research and implementation of technology, systems, and applications related to the convergence of supercomputing, big data, and artificial intelligence at the National Supercomputing Guangzhou Center. His researches have been published in some top-tier conferences and journals, including IEEE TC, IEEE TPDS, SC, IEEE IPDPS, ICS, PPoPP and IEEE DAC.

Alison Clear
Eastern Institute of Technology, New Zealand
Vice Chair
ACM Special Interest Group in Computer Science Education
Alison Clear is an associate professor and programme leader at the Auckland campus of the Eastern Institute of Technology. She has an extensive academic and professional career that has involved academic leadership in research, scholarship, teaching and curriculum development nationally and internationally and an extensive publication record in national and international conferences and journals in computing and information technology. Alison has been a member of the international ACM Educational Council, member and vice chair of the ACM Special Interest Group in Computer Science Education and Fellow of the Institute of Information Technology Professionals (IITP) and Fellow of the Computing and Information Technology Research and Education in New Zealand (CITRENZ). She is currently leading an international research project of 36 people from 20 countries to redefine the computing curricula for 2020 forward.
A Model for Development of Computing Curricula and Keeping Abreast of Technology
For many years the ACM and IEEE have developed curriculum guidelines for the now seven computing disciplines. These guidelines have been instrumental in helping computing educators globally to define and design the curricula within their own universities. With the fast pace of technology these guidelines need updating on a regular basis, technology is moving faster than they can be updated. To update a set of curricula it takes a Task Force of approximately 10 people covering geographical areas as well as competency across the discipline, at present change it is too long, costly and not timely. To keep pace with the fast pace of technology and changing landscape of computing a project to design and implement a model for a “Living Curriculum” has been established.This model will be available to meet the needs of each of the disciplines and enable fast efficient update to the curriculum. It will be community sourced, moderated and on-going. This address will describe the background to the project and present the model that has been developed to implement a “Living Curriculum” .

Guangchun Zhang
Harbin Institute of Technology, China
Dr. Guangchun Zhang is an associate professor and Ph.D. supervisor in the School of Energy Science and Engineering at Harbin Institute of Technology. He received his B.S., M.S., and Ph.D. degrees from Xi’an Jiaotong University. Following graduation, he served as an Assistant Researcher at the Beijing Institute of Applied Physics and Computational Mathematics, completed postdoctoral research at Purdue University, and was a Research Fellow at the University of Michigan. His research interests include advanced numerical algorithms for the neutron transport equation,massively parallel computing, multiphysics coupling methods, and advanced nuclear reactor design. Dr. Zhang has led or contributed to the development of several high-performance neutron transport codes — NECP-Hydra, JSNT, Marvin, and PROTEUS-MOC — and has secured funding for more than ten projects from the National Natural Science Foundation of China and various provincial-level agencies.